
How to engineer an OpenLDAP directory service to create a unified login for heterogeneous environments.
Directory services is one of the most interesting and crucial parts of computing today. They provide our account management, basic authentication, address books and a back-end repository for the configuration of many other important applications.
It's been nine long years since Craig Swanson and Matt Lung originally wrote their article “OpenLDAP Everywhere” (LJ, December 2002), and almost six years since their follow-up article “OpenLDAP Everywhere Revisited” (LJ, July 2005).
In this multipart series, I cover how to engineer an OpenLDAP directory service to create a unified login for heterogeneous environments. With current software and a modern approach to server design, the aim is to reduce the number of single points of failure for the directory.
In this article, I describe how to configure two Linux servers to host core network services required for clients to query the directory service. I configure these core services to be highly available through the use of failover pools and/or replication.
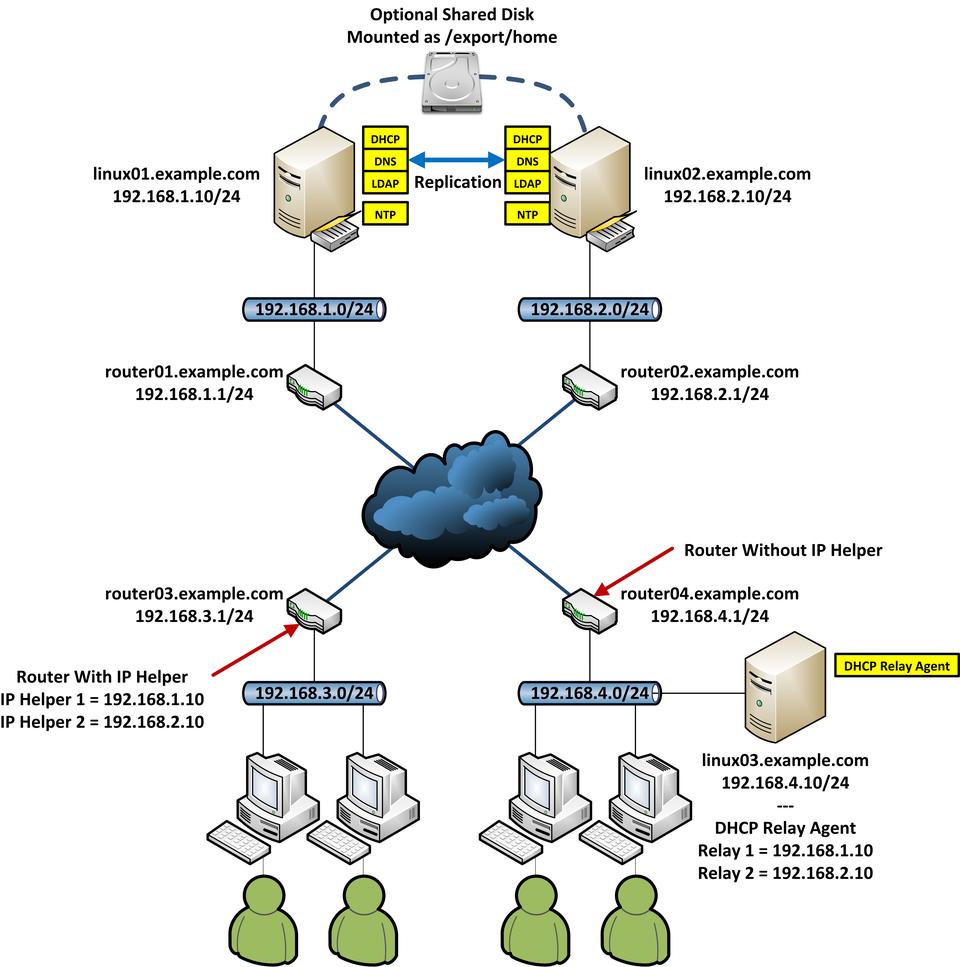
Figure 1. An Overall View of Core Network Services, Including LDAP (Note: the image of the hard disk icon in this figure was taken from the Open Icon Library Project: openiconlibrary.sourceforge.net.)
Certain approaches were taken in this design with small-to-medium enterprises (SMEs) in mind. You may wish to custom-tailor the design if you are a small-to-medium business (SMB) or large-scale enterprise.
The servers discussed in this article were installed with the latest stable version of the Debian GNU/Linux. At the time of this writing, this was Debian 6.0.2.1 (Squeeze). Although it has not been tested for Ubuntu, Ubuntu users should be able to log in as root (run sudo su -) and have few problems.
As per Figure 1, the fictional local domain name is example.com. Four fictitious subnetworks exist: 192.168.1.0/24, 192.168.2.0/24, 192.168.3.0/24 and 192.168.4.0/24. Routing between the four subnets is assumed to be working correctly. Where appropriate, please substitute applicable values for your domain name, IP addresses, netmask addresses and so on.
LDAP users are assumed to have home directories in /export/home rather than /home. This allows LDAP credentials to be compatible for operating systems other than Linux. Many proprietary UNIXes, for example, use /export/home as the default home directory. /home on Solaris is also reserved for other purposes (automount directories).
The design assumes that /export/home is actually a shared disk.
This is typically implemented as a mountpoint to an NFS server on a host or NAS; however, the design makes no determination about how to achieve the shared disk, which is beyond the scope of the article, so I'm leaving it to the reader to decide how to implement this.
You can opt not to implement the shared disk, but there are some serious drawbacks if you don't. All LDAP users will need their $HOME directory to be created manually by the administrator for every server to which they wish to log in (prior to them logging in). Also, the files a user creates on one server will not be available to other servers unless the user copies them to the other server manually. This is a major inconvenience for users and creates a waste of server disk space (and backup tape space) because of the duplication of data.
All example passwords are set to “linuxjournal”, and it's assumed you'll replace these with your own sensible values.
On both linux01.example.com and linux02.example.com, use your preferred package manager to install the ntp, bind9, bind9utils, dnsutils, isc-dhcp-server, slapd and ldap-utils packages.
Accurate timekeeping between the two Linux servers is a requirement for DHCP failover. There are additional benefits in having accurate time, namely:
It's required if you intend to implement (or already have implemented) secure authentication with Kerberos.
It's required if you intend to have some form of Linux integration with Microsoft Active Directory.
It's required if you intend to use N-Way Multi-Master replication in OpenLDAP.
It greatly assists in troubleshooting, eliminating the guesswork when comparing logfile timestamps between servers, networking equipment and client devices.
Once ntp is installed on both linux01.example.com and linux02.example.com, you are practically finished. The Debian NTP team creates very sensible defaults for ntp.conf(5). Time sources, such as 0.debian.pool.ntp.org and 1.debian.pool.ntp.org, will work adequately for most scenarios.
If you prefer to use your own time sources, you can modify the lines beginning with server in /etc/ntp.conf. Replace the address with that of your preferred time source(s).
You can check on both servers to see if your ntp configuration is correct with the ntpq(1) command:
root@linux01:~# ntpq -p
remote refid st t when poll reac
h delay offset jitter
====================================================
==========================
+warrane.connect 130.95.179.80 2 u 728 1024 377
74.013 -19.461 111.056
+a.pool.ntp.uq.e 130.102.152.7 2 u 179 1024 377
79.178 -14.069 100.659
*ntp4.riverwillo 223.252.32.9 2 u 749 1024 377
76.930 -13.306 89.628
+c122-108-78-111 121.0.0.42 3 u 206 1024 377
78.818 6.485 72.161
root@linux01:~#
Don't be concerned if your ntpq output shows a different set of servers. The *.pool.ntp.org addresses are DNS round-robin records that balance DNS queries among hundreds of different NTP servers. The important thing is to check that ntp can contact upstream NTP servers.
If the LDAP client can't resolve the hostname of the Linux servers that run OpenLDAP, they can't connect to the directory services they provide. This can include the inability to retrieve basic UNIX account information for authentication, which will prevent user logins.
As such, configure ISC bind to provide DNS zones in a master/slave combination between the two Linux servers. The example workstations will be configured (through DHCP) to query DNS on linux01.example.com, then linux02.example.com if the first query fails.
Note: /etc/bind/named.conf normally is replaced by the package manager when the bind9 package is upgraded. Debian's default named.conf(5) has an include /etc/bind/named.conf.local statement so that site local zone configurations added there are not lost when the bind9 package is upgraded.
On linux01.example.com, modify /etc/bind/named.conf.local to include the following:
//// excerpt of named.conf.local on linux01
// --- Above output suppressed
zone "168.192.in-addr.arpa" {
type master;
file "/etc/bind/db.168.192.in-addr.arpa";
notify yes;
allow-transfer { 192.168.2.10; }; // linux02
};
zone "example.com" {
type master;
file "/etc/bind/db.example.com";
notify yes;
allow-transfer { 192.168.2.10; }; // linux02
};
// --- Below output suppressed
On linux01.example.com, create the zone files /etc/bind/db.168.192.in-addr.arpa and /etc/bind/db.example.com, and populate them with appropriate zone information. For very basic examples of the zone files, see the example configuration files available on the LJ FTP site (see Resources for the link).
Before committing changes to a production DNS server, always check that no mistakes are present. Failure to do this causes the named(8) dæmon to abort when restarted. You don't want to cause a major outage for production users if there is a trivial error. On linux01.example.com:
# named-checkconf /etc/bind/named.conf # named-checkconf /etc/bind/named.conf.local # named-checkzone 168.192.in-addr.arpa /etc/bind/db. 168.192.in-addr.arpa zone 168.192.in-addr.arpa/IN: loaded serial 20111003 01 OK # named-checkzone example.com /etc/bind/db.example.c om zone example.com/IN: loaded serial 2011100301 OK #
On linux01.example.com, instruct the named(8) dæmon to reload its configuration files, then check that it didn't abort:
root@linux01:~# /etc/init.d/bind9 reload Reloading domain name service...: bind9. root@linux01:~# ps -ef|grep named|grep -v grep bind 1283 1 0 16:05 ? 00:00:00 /usr /sbin/named -u bind root@linux01:~#
It is possible during normal operations that the named(8) dæmon on linux01.example.com could abort and the rest of the server would otherwise continue to function as normal (that is, single service failure, not entire server failure). As linux02.example.com will have a backup copy of the zones anyway, linux01.example.com should use linux02.example.com as its secondary DNS server.
On linux01.example.com, create and/or modify /etc/resolv.conf. Populate it with the following:
search example.com nameserver 127.0.0.1 nameserver 192.168.2.10
On linux01.example.com, check, and if necessary, modify /etc/nsswitch.conf to include the following “hosts” definition. This line already was in place for me, but it strictly does need to be present for you if it isn't:
## /etc/nsswitch.conf on linux01 & linux02 # --- Above output suppressed hosts: files dns # --- Below output suppressed
Finally, test that linux01.example.com can resolve records from the DNS server:
root@linux01:~# dig linux02.example.com +short 192.168.2.10 root@linux01:~# dig -x 192.168.2.10 +short linux02.example.com. root@linux01:~# nslookup linux02.example.com Server: 127.0.0.1 Address: 127.0.0.1#53 Name: linux02.example.com Address: 192.168.2.10 root@linux01:~# nslookup 192.168.2.10 Server: 127.0.0.1 Address: 127.0.0.1#53 10.2.168.192.in-addr.arpa name = linux01.example.com. root@linux01:~#
Now, configure linux02.example.com as the slave server. First, modify /etc/bind/named.conf.local to include the following:
//// excerpt of named.conf.local on linux02
// --- Above output suppressed
zone "168.192.in-addr.arpa" {
type slave;
file "/var/lib/bind/db.168.192.in-addr.arpa";
masters { 192.168.1.10; }; // the linux01 server
};
zone "example.com" {
type slave;
file "/var/lib/bind/db.example.com";
masters { 192.168.1.10; }; // the linux01 server
};
// --- Below output suppressed
Take careful note of the placement of the slave zone files in /var/lib/bind, not in /etc/bind!
This change is for two reasons. First, /etc/bind is locked down with restrictive permissions so named(8) is not able to write any files there. named(8) on linux02.example.com cannot and should not write a transferred zone file there.
Second, the /var partition is intentionally designated for files that will grow over time. /var/lib/bind is the Debian chosen directory for named(8) to store such files.
Please resist the urge to change permissions to “fix” /etc/bind! I cannot stress this enough. It not only compromises the security on your RNDC key file, but also the dpkg package manager is likely to revert any change you made on /etc/bind the next time the bind9 package is upgraded.
If you require a single location for both servers to store their zone files, it would be better to move the local zone files on linux01.example.com to /var/lib/bind, rather than force a change to /etc/bind on linux02.example.com. Don't forget to update the paths for the zone files in linux01.example.com's /etc/bind/named.conf.local accordingly.
On linux02.example.com, run named-checkconf(1) to check the new configuration, as you did before for linux01.example.com. If the new configuration checks out, tell named(8) to reload by running the /etc/init.d/bind9 reload command. Also check that the dæmon didn't abort by running ps -ef|grep named|grep -v grep as was done before.
If the zone transfer from linux01.example.com was successful, you should have something like the following appear in /var/log/syslog on linux02.example.com:
# --- above output suppressed --- Oct 3 20:37:11 linux02 named[1253]: transfer of '168 .192.in-addr.arpa/IN' from 192.168.1.10#53: connected using 192.168.2.10#35988 --- output suppressed --- Oct 3 20:37:11 linux02 named[1253]: transfer of '168 .192.in-addr.arpa/IN' from 192.168.1.10#53: Transfer completed: 1 messages, 12 records, 373 bytes, 0.001 secs (373000 bytes/sec) --- output suppressed --- Oct 3 20:37:12 linux02 named[1253]: transfer of 'exa mple.com/IN' from 192.168.1.10#53: connected using 1 92.168.2.10#41155 --- output suppressed --- Oct 3 20:37:12 linux02 named[1253]: transfer of 'exa mple.com/IN' from 192.168.1.10#53: Transfer complete d: 1 messages, 12 records, 336 bytes, 0.001 secs (33 6000 bytes/sec) # --- below output suppressed ---
On linux02.example.com, create and/or modify /etc/resolv.conf. Populate it with the following:
search example.com nameserver 127.0.0.1 nameserver 192.168.1.10
This is the only device on the network that will ever have linux02.example.com as its primary DNS server. It's done for performance reasons, on the assumption that linux01.example.com will fail first. Of course, you never can predict which server will fail first. However, if linux02.example.com happens to fail first, the workstations, in theory, won't notice it—DHCP tells them to query linux01.example.com before linux02.example.com.
Now, on linux02.example.com, check, and if necessary, modify /etc/nsswitch.conf to include the hosts: files dns in the same way performed previously. Check that dig(1) and nslookup(1) can resolve linux01.example.com in a similar manner as done before.
If your LDAP clients can't receive an IP address to communicate with the network, they can't communicate with the OpenLDAP servers.
As such, configure ISC dhcpd to use failover pools between the two Linux servers. This ensures that IP addresses always are being handed out to clients. It also ensures that the two Linux servers are not allocating the duplicate addresses to the workstations.
The failover protocol for dhcpd is still in development by ISC at the time of this writing, but it is subject to change in the future. It works fairly well most of the time in its current state, and it's an important part of mitigating the risk of server failure for the directory service.
Create a new file on both linux01.example.com and linux02.example.com by running the command touch /etc/dhcp/dhcpd.conf.failover.
Separate the failover-specific configuration from the main /etc/dhcp/dhcpd.conf file. That way, /etc/dhcp/dhcpd.conf can be synchronized between both servers without destroying the unique configuration in the “failover peer” stanza. You never should synchronize /etc/dhcp/dhcpd.conf.failover between the two Linux servers.
On linux01.example.com, populate /etc/dhcp/dhcpd.conf.failover as follows:
failover peer "dhcp-failover" {
primary;
address linux01.example.com;
port 519;
peer address linux02.example.com;
peer port 520;
max-response-delay 60;
max-unacked-updates 10;
load balance max seconds 3;
mclt 3600;
split 128;
}
Notice that the parameters split and mclt are specified only on the primary server linux01.example.com.
max-response-delay controls how many seconds one server will wait for communication from the other before it assumes a failure.
split controls how many IP addresses available in the pool are pre-allocated to each DHCP server. The only valid values are from 0 to 255. As per the example, a split 128; value governs that each server takes 50% of the leases of the entire pool.
On linux02.example.com, populate /etc/dhcp/dhcpd.conf.failover as follows:
failover peer "dhcp-failover" {
secondary;
address linux02.example.com;
port 520;
peer address linux01.example.com;
peer port 519;
max-response-delay 60;
max-unacked-updates 10;
load balance max seconds 3;
}
Note: IANA has not allocated a reserved port number for ISC dhcpd failover at the time of this writing. This means the port/peer port numbers of 519 and 520 are subject to change.
On both linux01.example.com and linux02.example.com, you now should populate /etc/dhcp/dhcpd.conf with appropriate subnet information. For a very basic example of dhcpd.conf, see the example configuration files provided in the Resources section.
The crucial parameters to have in /etc/dhcp/dhcpd.conf are:
# excerpt of dhcpd.conf on linux01 and linux02
#-----------------
# Global DHCP parameters
#-----------------
# --- outputs heavily suppressed ----
#-----------------
# Failover parameters
#-----------------
include "/etc/dhcp/dhcpd.conf.failover";
# --- outputs heavily suppressed ---
subnet 192.168.3.0 netmask 255.255.255.0 {
option routers 192.168.3.1;
option subnet-mask 255.255.255.0;
option broadcast-address 255.255.255.255;
pool {
failover peer "dhcp-failover";
range 192.168.3.20 192.168.3.250;
}
}
subnet 192.168.4.0 netmask 255.255.255.0 {
option routers 192.168.4.1;
option subnet-mask 255.255.255.0;
option broadcast-address 255.255.255.255;
pool {
failover peer "dhcp-failover";
range 192.168.4.20 192.168.4.250;
}
}
These parameters alone are not enough to get a new DHCP server up and running. But, once a working dhcpd.conf is built for your network, add the above parameters for DHCP failover.
Restart dhcpd(8) on both linux01.example.com and linux02.example.com. Do this by running the command /etc/init.d/isc-dhcp-server restart. Check that the dhcpd(8) process did not abort by running ps -ef|grep dhcpd|grep -v grep.
If dhcpd(8) is no longer running, the problem is usually a typo. Re-check in dhcpd.conf and dhcpd.conf.failover that every opening parenthesis (the { character) has a closing parenthesis (the } character). Also check that lines not ending with open/closed parentheses are terminated by a semicolon (;).
Check /var/log/syslog on both servers for messages from dhcpd. When DHCP failover works, both servers should say the pool is “balanced”, and that “I move from communications-interrupted to normal” or “I move from startup to normal”.
Synchronize /etc/dhcp/dhcpd.conf from linux01.example.com to linux02.example.com every time you modify it. This can be done manually, via an rsync(1) script, via puppetd(8) or via the Network Information Service (though I don't recommend NIS—it's insecure and obsoleted by DNS/LDAP and rsync/puppet).
The drawback to the failover protocol is that it's a long way off from being considered mature. There are plenty of weird situations where the protocol fails to do its job. However, it will not be young forever, and when it does work, it works well. I recommend you monitor your logs and sign up to ISC's dhcp-users mailing list for assistance when things go wrong (see Resources for a link).
One last note on the DHCP failover protocol: if you have more devices on one subnet than 50% of the overall amount available in the pool range, seriously consider re-engineering your network before implementing DHCP failover.
The protocol inherently relies on having an excess of free addresses to allocate, even after the pool range is cut in half by split 128;.
The maximum amount of available IP addresses for DHCP in a C Class subnet most of the time is 253 (255 addresses, minus 1 address for broadcast, minus 1 address for the router).
If you have more than 126 devices within one failover subnet, either split it into more subnets (for example, one subnet for each floor of the building), or use a larger subnet than C Class. Configure the subnet declaration in /etc/dhcpd.conf to increase its pool range accordingly. It will save you problems later on.
Now that the DHCP servers are configured with failover pools, the final thing to do is configure the 192.168.3.0/24 and 192.168.4.0/24 to forward DHCP client broadcasts through the LAN/WAN to 192.168.1.10 and 192.168.2.10.
This is done on router03.example.com with IP Helper addresses. On linux03.example.com, it's done with ISC's DHCP Relay Agent.
Assume router03.example.com is a Cisco Catalyst Multi-layer Switch. Configure IP Helper addresses by entering privileged mode (run the enable command). Using the ip helper-address command, apply the two DHCP server IP addresses to the router interface that has the 192.168.3.1/24 address. On the Catalyst 3750G in my lab, this is interface “vlan20”. The commands are applied like so:
router03#show running-config Building configuration... --- output suppressed --- interface Vlan20 description linuxjournal_vlan ip address 192.168.3.1 255.255.255.0 end --- output suppressed --- router03#configure terminal router03(config)#interface vlan 20 router03(config-if)#ip helper-address 192.168.1.10 router03(config-if)#ip helper-address 192.168.2.10 router03(config-if)#end router03#copy running-config startup-config Destination filename [startup-config]? Building configuration... [OK] 0 bytes copied in 8.715 secs (0 bytes/sec) router03#show running-config interface vlan 20 Building configuration... Current configuration : 154 bytes ! interface Vlan20 description linuxjournal_vlan ip address 192.168.3.1 255.255.255.0 ip helper-address 192.168.1.10 ip helper-address 192.168.2.10 end router03#
On linux03.example.com, you need to install the isc-debian-relay package. Once it's installed, it will ask for the “multiple server names be provided as a space-separated list”. Enter “linux01.example.com linux02.example.com”, or if this host isn't configured to resolve from our DNS server pair, “192.168.1.10 192.168.2.10”. It will ask on which interface to listen. If you have no preference, leave it blank and press Enter. It will ask you to specify additional options, but you simply can press Enter.
If you make a mistake, you can reconfigure by running the command dpkg-reconfigure isc-dhcp-relay or modify the SERVERS variable in /etc/default/isc-dhcp-relay.
Your DHCP clients now should be able to contact either DHCP server.
In Part II of this series, I'll explain how to configure OpenLDAP on the two Linux servers and start to populate the directory with data.
