
In high-availability clusters, redundancy of data is just as crucial as redundancy of nodes. In the second installment of his series on high availability, Florian Haas explains building rock-solid, block-replicated iSCSI data storage with Pacemaker and DRBD.
Any high-availability solution is only as good as its data. Historically, high-availability clusters often have single-instance, hardware-based storage solutions—the classic and widespread SAN. Interestingly, this is one of the few remaining strongholds of proprietary solutions, even in environments that are otherwise dominated by open-source technology. It's also often an extremely expensive stronghold.
The first article in this series on Linux high availability covered the basics of the stack, taking storage for granted [see Florian's article “Ahead of the Pack: the Pacemaker High-Availability Stack” in the April 2012 issue]. This installment covers building redundant, automatically replicated, highly available cluster storage that can act as a drop-in replacement for costly and proprietary SAN-based solutions.
The highly available storage stack on Linux centers predominantly on iSCSI, an implementation of the SCSI protocol over IP networks. iSCSI, defined in RFC 3720 back in 2004, has become a widely adopted and supported standard for SAN connectivity, largely displacing Fibre Channel-based SANs in many shops. iSCSI, normally TCP-based with optional support for RDMA-capable protocols, such as InfiniBand, could be described as a client/server protocol, but that's confusing, as the iSCSI “client” is very often an application “server” in the conventional sense. Hence, iSCSI sticks to the conventional SCSI terms of “target” (the thing that stores the data physically) and “initiator” (the thing that accesses the data over the wire).
As far as the initiator side is concerned, there's a clearly dominant solution in a Linux environment, and that is the open-iscsi Project. Supported by all major distros and iSCSI vendors, open-iscsi, although not flawless throughout its existence, is now ubiquitous and widely accepted as the reference iSCSI initiator on Linux.
For targets, things are a bit more complicated. No fewer than four open-source iSCSI targets currently are available to the Linux storage specialist.
IET, the iSCSI Enterprise Target, is an iSCSI-only, in-kernel implementation of a target that is available as an out-of-tree kernel module only. IET came out of a proprietary iSCSI target implementation from Netherlands-based Ardis Technologies, forked under GPL terms. It enjoys a remarkable proliferation among vendors of cheap iSCSI storage appliances. Several distributions, including SUSE and Debian/Ubuntu, ship IET. Its development is ongoing, but humming along quietly under most people's radar. Scott Walker and Arne Redlich are currently the project's main developers.
With STGT, ex-IET maintainer Fujita Tomonori intended to write an all-userspace, multiple-protocol replacement for IET. It uses only a tiny, generic stub of in-kernel code that made it into Linux at the 2.6.20 release. Everything else about the target happens in userland. Red Hat was quick to adopt STGT as its default iSCSI target during the Red Hat Enterprise Linux (RHEL) 5 release cycle, and continues to support it through RHEL 6. SUSE also has adopted it for SUSE Linux Enterprise Server (SLES) 11, and it also ships in Debian and Ubuntu. However, active development on STGT seems to have largely ceased, and the project is in maintenance-only mode.
SCST, maintained primarily by Vladislav Bolkhovitin and Bart van Assche, is another IET fork with the goal of fixing “all the problems, corner cases issues and iSCSI standard violations that IET has”, as the project boldly states on its Web site. SCST has a large and devoted following, and SCST users primarily laud its performance benefits over the competing target implementations. Contrary to STGT and similar to IET, SCST does a lot of its work in the kernel, and its developers have repeatedly submitted the target for inclusion in the mainline kernel. Thus far, however, these efforts have been unsuccessful—at least partially because a fourth target beat developers to it.
That fourth target is LIO, named after the “linux-iscsi.org” domain that the project owns. Its main developer is Nicholas Bellinger. LIO is a generic, in-kernel target driver, of which the iSCSI target is merely one of many front ends. Of the four targets mentioned here, it is the only one not interrelated with any other, and that's not its only interesting trait. LIO uses an unusual in-kernel configuration approach using ConfigFS, which has produced some interesting flame wars on the linux-kernel mailing list in years past. However, in early 2011, LIO beat out SCST to become the blessed replacement of STGT as the upstream kernel's preferred target subsystem. As upstream kernel releases trickle into distributions slowly, some distros already have incorporated this upstream change, but most have not.
Any of the four iSCSI targets just mentioned would enable us to build stable, fully open-source, single-instance iSCSI storage on Linux. But that would violate the three Rs of high availability: Redundancy, Redundancy, Redundancy. Storing all of our data just once isn't good enough. We'll need at least two copies of every block we store to remain available even in the face of a storage node failing.
That's where DRBD comes in. Originally the “Distributed Replicated Block Device”, it's a synchronous replication facility in the kernel block layer. DRBD provides a virtual block device type (with the LANANA-registered major number of 147) with unique characteristics: any write I/O it receives passes down into the local block layer and simultaneously into the network stack. Over the wire, data replicates to another node—the DRBD peer—where it again passes through the local I/O subsystem and on to directly attached storage. The synchronous nature of DRBD's replication ensures that any writes to the device complete only when completed on both nodes. As such, its replication is fully transparent to applications.
Obviously, if one of the nodes fails, DRBD automatically switches itself into disconnected mode: rather than persisting in its temporarily pointless quest to replicate, it starts recording addresses of out-of-sync blocks in a persistent bitmap. Once the previously failed node recovers, DRBD re-synchronizes the changed data quickly and efficiently.
DRBD's overall overhead is surprisingly small. Its impact on read performance is practically nil, as reads are local to the host, without any network layer involved at all. For writes, throughput is practically unaffected by a well-tuned DRBD, although some highly latency-critical applications will be adversely affected by running on DRBD.
DRBD has had a somewhat colorful history with regard to its mainline Linux integration. For the better part of its lifetime, the developers chose to maintain the project as an out-of-tree module. Then in mid-2007, it made its first push toward mainline integration, meeting initial rejection from the kernel community—just like many projects with out-of-tree baggage. The developers then embarked on a massive cleanup process, culminating in a final pull request for the 2.6.32 kernel merge window. Following some last-minute opposition, Linus declined to pull DRBD for just that release, and DRBD finally made it into the kernel for 2.6.33 in February 2010.
Since then, the “official” DRBD codebase and the Linux kernel have again diverged, with the most recent DRBD releases remaining unmerged into the mainline kernel. A re-integration of the two code branches is currently, somewhat conspicuously, absent from Linux kernel mailing-list discussions. That situation has caused interesting disparities regarding the state of vendor support for DRBD. Some distributions, like Debian and Ubuntu, currently ship DRBD kernel code as part of their standard kernel packages. Others, like SLES, ship the out-of-tree kernel module version. Still others, like RHEL, do not ship DRBD at all and rely on outside packaging contributions from CentOS and ELRepo. At any rate, to use DRBD, two components are required at a minimum: the DRBD kernel mode itself and a set of userspace utilities and shell scripts that ship as part of the drbd-utils (drbd8-utils on Debian-like platforms) package. On a system where those packages are available, setting up a replicated data set—in DRBD-speak, a “resource”—amounts to a sequence of these steps:
Set aside a block device for DRBD's local use. DRBD refers to this as its “backing device”. This can be an SCSI LUN, a disk partition, an LVM logical volume or any other Linux block device you can possibly imagine.
Create a resource definition file in /etc/drbd.d.
Initialize DRBD's metadata.
Enable the DRBD resource.
Kick off the initial full-device synchronization to make sure your data sets are in perfect unison (this step can be skipped if the devices are fresh off the assembly line and known to be identical in content).
Start using the device as any other block device.
Creating a logical volume or partitioning a disk is certainly no challenge for the intrepid reader. Creating a DRBD resource definition, in contrast, might be. DRBD is known for its myriad configuration options, but it also holds some renown for coming with excellent documentation, and simple baseline resource configurations like the following are easy to obtain from the comprehensive DRBD User's Guide:
resource vg1 {
device /dev/drbd0;
disk /dev/sdc;
meta-disk internal;
on mike {
address 192.168.43.111:7788;
}
on nancy {
address 192.168.43.112:7788;
}
}
This configures a resource named vg1 running the DRBD device /dev/drbd0, which mirrors the SCSI device /dev/sdc between hosts mike and nancy. It replicates on TCP port 7788 between the 192.168.133.111 and 192.168.133.112 IP addresses. meta-disk internal simply means that DRBD sticks its own metadata into the last few blocks of /dev/sdc. This doesn't mean /dev/drbd0 will be orders of magnitude smaller than the underlying /dev/sdc—DRBD requires only about 32kB of metadata per replicated Gigabyte.
Once the /dev/sdc devices are available on both nodes mike and nancy, and so is the just-created resource definition file, you can continue with initializing the device:
drbdadm create-md vg1 v08 Magic number not found Writing meta data... initialising activity log NOT initialized bitmap New drbd meta data block successfully created. success
It is necessary to complete this step on both nodes: the metadata that this command creates is local to each individual DRBD node. Likewise, it's necessary to activate the device on both nodes:
drbdadm up vg1
And finally, on one node only, it is time to kick off the initial device synchronization with a command that sticks out for its somewhat peculiar use of hyphens and whitespace:
drbdadm -- --force primary vg1
From this point forward, you may use the device as any other block device, the ongoing background synchronization notwithstanding (this will sound highly familiar to mdadm users).
For most use cases, the next step would be to create a filesystem on the DRBD device. But because DRBD is just another block device, you can treat it as exactly that, and you're essentially free to do anything you would with a “normal”, non-replicated block device. In this case, let's create an LVM Physical Volume (PV) signature and a Volume Group (VG):
pvcreate /dev/drbd0 vgcreate vg1 /dev/drbd0
Once that volume group exists, you can use it like any other—for example, you can create a 10-Gigabyte Logical Volume from it:
lvcreate -L 10G -n lun1 vg1
And this logical volume, along with the rest of its VG, is now available on whichever node currently has the underlying DRBD resource in the Primary role. You easily can try this out:
mike:# vgchange -a n vg1 mike:# drbdadm secondary vg1 nancy:# drbdadm primary vg1 nancy:# vgchange -a y vg1
Thereafter, /dev/vg1/test is available as a block device on nancy. The steps you just manually completed are, of course, a cluster manager's task to handle automatically, as I'll explain in a moment.
In combining DRBD and LVM with a Linux iSCSI target, you can create fully replicated, redundant SAN storage in Linux. You need only a cluster manager to tie everything together.
As for any Pacemaker cluster, you first need to set up the underlying Corosync cluster messaging layer. Let's use a configuration that is substantially identical to that in the first article in this series, where I explained the basics of Corosync in more detail:
totem {
# Enable node authentication & encryption
secauth: on
# Redundant ring protocol: none, active, passive.
rrp_mode: active
# Redundant communications interfaces
interface {
ringnumber: 0
bindnetaddr: 192.168.0.0
mcastaddr: 239.255.30.11
mcastport: 5405
}
interface {
ringnumber: 1
bindnetaddr: 192.168.43.0
mcastaddr: 239.255.43.0
mcastport: 5405
}
}
amf {
mode: disabled
}
service {
# Load Pacemaker
ver: 1
name: pacemaker
}
logging {
fileline: off
to_stderr: yes
to_logfile: no
to_syslog: yes
syslog_facility: daemon
debug: off
timestamp: on
}
Attentive readers immediately will realize that this example uses multicast addresses different from the ones in my previous article. This is a generally established Corosync best practice: never reuse cluster communications multicast addresses across multiple distinct clusters sharing one host network. Cluster nodes will not join rogue clusters due to mutual node authentication via the Corosync “authkey” shared secret, but they will multicast cluster communications to hosts that aren't supposed to see them. Allocating a new multicast group to each cluster on the network eliminates this issue.
The actual Pacemaker configuration is one that you can, again, either implement on a step-by-step, interactive basis, or you can import it all in one fell swoop, thanks to the crm shell being fully scriptable:
primitive p_drbd_vg1 ocf:linbit:drbd \
params drbd_resource="vg1" \
op monitor interval="30" role="Slave" \
op monitor interval="10" role="Master"
ms ms_drbd_vg1 p_drbd_vg1 \
meta interleave="true" notify="true"
primitive p_lvm_vg1 ocf:heartbeat:LVM \
params volgrpname="vg1" \
op monitor interval="30"
primitive p_target_vg1 ocf:heartbeat:iSCSITarget \
params implementation="tgt" \
iqn="iqn.2001-04.com.example:example.vg1" \
tid="1" \
additional_parameters="DefaultTime2Retain=60 DefaultTime2Wait=5" \
op monitor interval="10"
primitive p_lu_vg1_lun1 \
ocf:heartbeat:iSCSILogicalUnit \
params lun="1" path="/dev/vg1/lun1" \
target_iqn="iqn.2001-04.com.example:vg1" \
op monitor interval="10"
primitive p_ip_vg1 ocf:heartbeat:IPaddr2 \
params ip="192.168.0.100" cidr_netmask="24" \
op monitor interval="10"
group g_vg1 \
p_lvm_vg1 p_target_vg1 p_lu_vg1_lun1 p_ip_vg1
order o_drbd_before_vg1 inf: \
ms_drbd_vg1:promote g_vg1:start
colocation c_vg1_on_drbd inf: \
g_vg1 ms_drbd_vg1:Master
This configuration creates an iSCSI target using the STGT implementation—the default on RHEL/CentOS and an available choice on SLES, Debian and Ubuntu—which uses the iSCSI Qualified Name “iqn.2001-04.com.example:vg1”. The target contains one Logical Unit with the Logical Unit Number (LUN) 1, and is available through the portal IP address 192.168.0.100 using the default iSCSI TCP port of 3260.
As usual, you can check Pacemaker's status with the crm_mon utility:
============
Last updated: Sun Mar 4 21:59:23 2012
Last change: Sun Mar 4 21:58:38 2012 via crm_attribute on mike
Stack: openais
Current DC: nancy - partition with quorum
Version: 1.1.6-4.el6-89678d4947c5bd466e2f31acd58ea4e1edb854d5
2 Nodes configured, 2 expected votes
6 Resources configured.
============
Online: [ mike nancy ]
Resource Group: g_vg1
p_lvm_vg1 (ocf::heartbeat:LVM): Started mike
p_target_vg1 (ocf::heartbeat:iSCSITarget): Started mike
p_lu_vg1_lun1 (ocf::heartbeat:iSCSILogicalUnit): Started mike
p_ip_vg1 (ocf::heartbeat:IPaddr2): Started mike
Master/Slave Set: ms_drbd_vg1 [p_drbd_vg1]
Masters: [ mike ]
Slaves: [ nancy ]
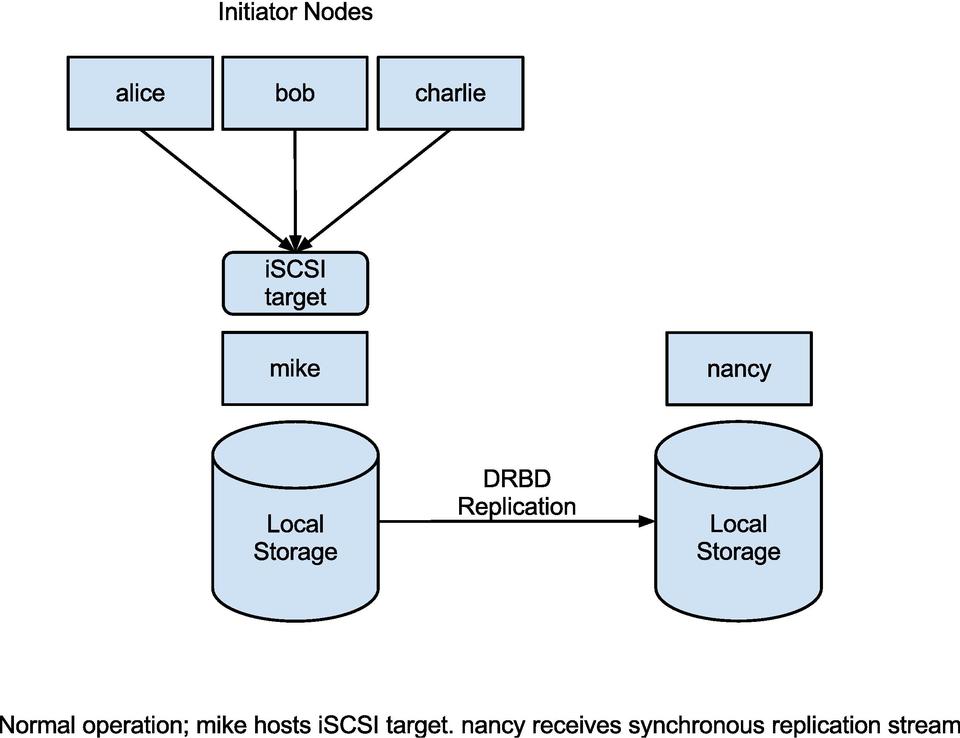
Figure 1. Normal operation: mike hosts iSCSI target; nancy receives synchronous replication stream.
Pacemaker, LVM and DRBD now jointly ensure that this specific target and LUN always are available on one of the cluster nodes. If the node hosting the target goes down—for reasons of node failure or scheduled maintenance—the entire stack simply shifts over to the other node:
============
Last updated: Sun Mar 4 22:01:15 2012
Last change: Sun Mar 4 22:01:12 2012 via crm_attribute on mike
Stack: openais
Current DC: nancy - partition with quorum
Version: 1.1.6-4.el6-89678d4947c5bd466e2f31acd58ea4e1edb854d5
2 Nodes configured, 2 expected votes
6 Resources configured.
============
Online: [ nancy ]
OFFLINE: [ mike ]
Resource Group: g_vg1
p_lvm_vg1 (ocf::heartbeat:LVM): Started nancy
p_target_vg1 (ocf::heartbeat:iSCSITarget): Started nancy
p_lu_vg1_lun1 (ocf::heartbeat:iSCSILogicalUnit): Started nancy
p_ip_vg1 (ocf::heartbeat:IPaddr2): Started nancy
Master/Slave Set: ms_drbd_vg1 [p_drbd_vg1]
Masters: [ nancy ]
Stopped: [ p_drbd_vg1:0 ]
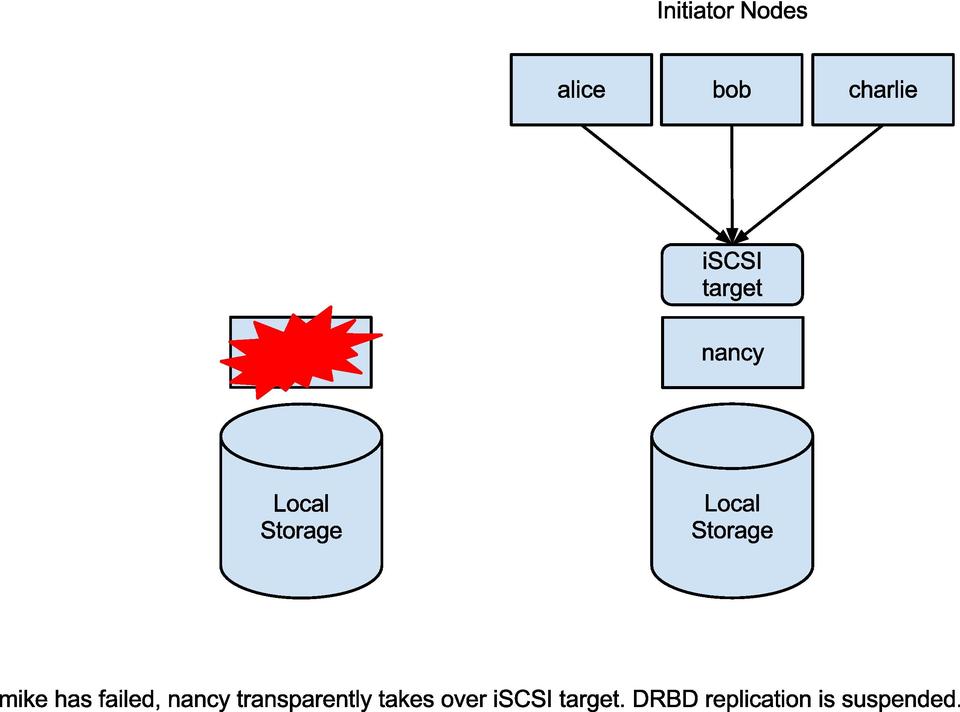
Figure 2. mike has failed; nancy transparently takes over iSCSI target. DRBD replication is suspended.
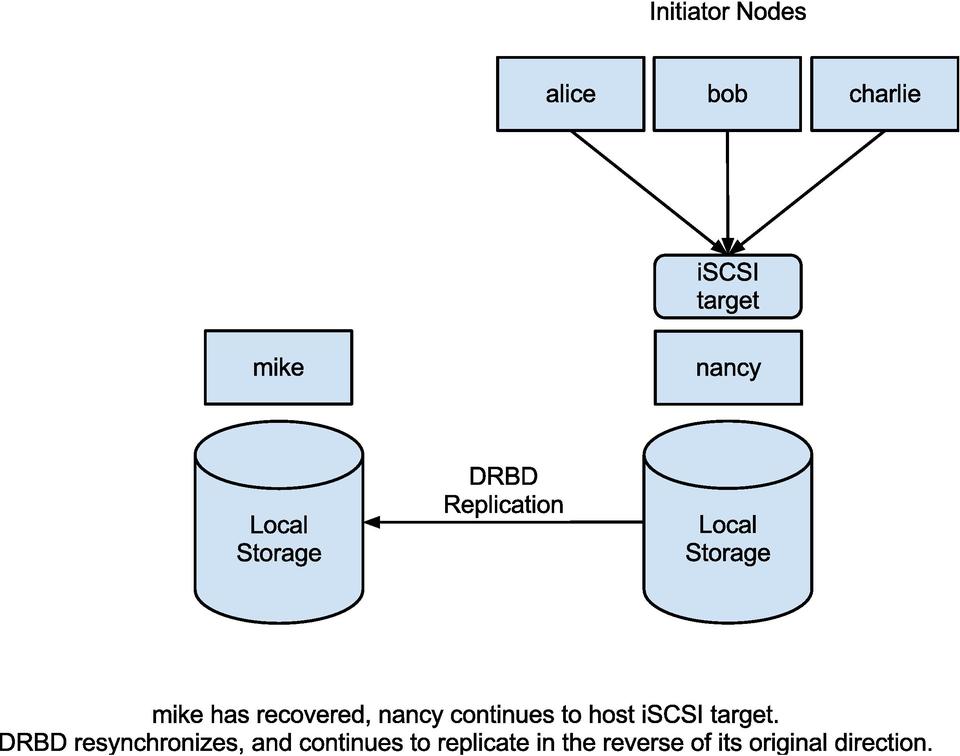
Figure 3. mike has recovered; nancy continues to host iSCSI target. DRBD resynchronizes and continues to replicate in the reverse of its original direction.
Adding more LUNs to the stack is a simple matter of creating more Logical Volumes in the DRBD-backed VG, then adding additional ocf:heartbeat:iSCSILogicalUnit resources to the g_vg1 group.
The iSCSI standard prescribes a per-connection iSCSI parameter, Time2Retain, that governs the length of a connection interruption that the initiator must tolerate. If the target goes away for a limited time—as in the case of a short network hiccup—the initiator simply blocks I/O on the affected iSCSI links. I/O resumes when the target returns. Only if the Time2Retain expires does it drop the connection and flag an I/O error. You can use this feature in building highly available iSCSI targets: as long as the cluster manages to complete failover within the time frame allotted by Time2Retain, the initiators simply resume I/O when the target comes alive on the second node. DRBD, for its part, guarantees through its synchronous replication that the new node has exactly the same data as the old one, so this resumption of I/O is perfectly safe as long as no volatile caches are involved.
The iSCSI initiator and target negotiate the Time2Retain parameter when connecting initially. Both present their preferred value, and the minimum presented value wins. Sadly, many iSCSI initiator implementations (the ubiquitous open-iscsi included) set this value to zero by default, thus forgoing a useful high-availability feature built right in to the iSCSI standard. However, they usually present a simple means of re-enabling it—in open-iscsi it's the DefaultTime2Retain parameter in the iscsid configuration file:
node.session.iscsi.DefaultTime2Wait = 60 node.session.iscsi.DefaultTime2Retain = 5
Setting these configuration parameters enables target failover that is smooth, transparent and almost interruption-free (except for a short, nonfatal I/O hang) to initiators.
The highly available, replicated storage stack I explored in this article is enormously solid, runs in production probably thousands of times over and has wide support from a variety of distributions. However, it does have its shortcomings when there are requirements for multinode replication, wide-area replication and scalability. In the next and final installment of this high-availability series, I will explore alternative approaches to replicated storage that promise to fix these issues.
